
Today we are thrilled to announce Madrona’s investment in MotherDuck.
MotherDuck is building a serverless easy-to-use data analytics platform based on the open-source project DuckDB. What Jordan Tigani and team have recognized is the opportunity to apply DuckDB for common and urgent enterprise analytics challenges. This team knows that enterprises care for ease of use, scalability, speed, and cost. And they’re extending DuckDB with additional capabilities that take advantage of the collaboration and scalability of the cloud to deliver better enterprise analytics.
Madrona has been fortunate to partner with amazing founders for many years in and around data infrastructure and enterprise analytics. Some of our investments in these areas have included Snowflake, Smartsheet, RelationalAI, FaunaDB, Observe, and Temporal. In Jon’s previous life, he also focused on edge computing and the power and opportunity of optimizing where each bit of data is processed. The “3 laws” — laws of physics, laws of economics, and laws of the land — have profound implications for the cost and benefit of locating those bits. MotherDuck has the opportunity to navigate those laws on behalf of customers and facilitate faster, cheaper, more accessible, and higher-quality decision-making with data.
Madrona has supported MotherDuck since “day zero” before the company was incorporated. We invested in the seed round and are thrilled to double down on that investment in the Series A.
Here are the three reasons we are so excited to invest in MotherDuck.
Remarkable Traction of DuckDB
Madrona has followed DuckDB closely since 2019 when Dr. Mark Raasveldt and Dr. Hannes Mühleisen created it at CWI in the Netherlands. We were excited about its technical properties (2MB runtime with no external dependencies, lightning speed, great SQL support, and the ability to easily stream data from larger data sources in chunks for real-time analytical queries without a traditional client/server connection). We have seen it get adopted in multiple parts of our portfolio and by some of the most sophisticated data teams in our network.
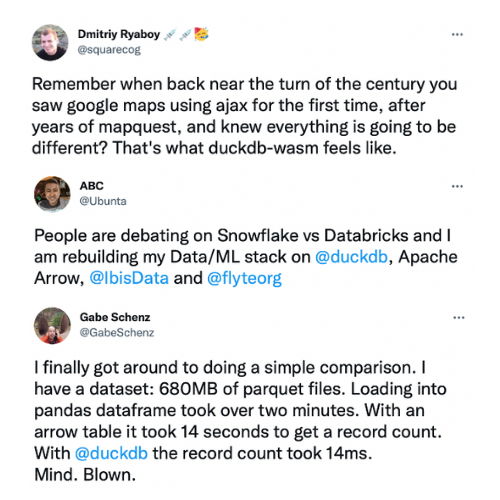
Today, the developer excitement is palpable. You can try to quantify this with the healthy and accelerating “star count” of developer interest on Github — more than 7,000 stars and rising for DuckDB. But the breadth and substance of developer interest turned out to be even more meaningful. Here are three tweets that reflect some of the things we heard privately in developer interviews:
Enterprise Analytics with MotherDuck
First, MotherDuck inherits DuckDB’s great SQL support, so it’s easy to use. Notwithstanding the petabyte scale of some analytics platforms built to support the world’s largest datasets, the reality of big data workloads is that most of the datasets are smaller than 100GB. That’s small enough to fit into the RAM of a single cloud host. The low overhead and easy integration of DuckDB means customers can run fast and easy analytical queries on those datasets without the compromises of a system optimized for petabyte-scale.
Second, MotherDuck is fast (low latency) even as the number of users increases (greater access). For the plurality of datasets that are just a few gigabytes in size (similar to a Netflix movie), MotherDuck can offload most of the work from the cloud to a browser tab. That means MotherDuck can avoid the oversubscription problems that come with traditional data warehouses. Think about this simple example: Data analysts typically expect data warehouses to be especially slow on Mondays due to recurring business reporting. But MotherDuck can work just as well — even on Mondays — by leveraging the compute on an analyst’s local machine, so more analysts can get more analysis done.
Third, MotherDuck has a different cost structure that can bring costs down for common analytics workloads. The team calls this “hybrid execution,” and it’s proprietary to MotherDuck, not part of DuckDB. Hybrid execution makes it possible to query a dataset spread across multiple places. Some data may be on an analyst’s laptop, some in a cloud endpoint, and another in a different cloud endpoint. MotherDuck makes it possible for an analyst to query the combination of these sources. MotherDuck intelligently decides the best location to process each bit of data, minimizing compute and data transfer costs.
Summing up, MotherDuck takes advantage of DuckDB and builds upon it to perform common types of analytical queries easily, quickly, with greater access, and lower cost than were possible before. All of this can ultimately help expand access to analytics and improve the quality of decisions that customers make with data.
Team
We have gotten to know the entire MotherDuck team well over the past several months, and we are thrilled with the caliber of this group Jordan has assembled. MotherDuck combines some of the best attributes of rich talent pools in the Pacific Northwest, NYC, and Western Europe. Plus, they benefit from the amazing contributions of Mark, Hannes, DuckDB Labs, CWI, and the vibrant open-source community that has emerged around DuckDB.
This team is experienced, thoughtful, and fun — one of them describes himself as a “wartime data engineer.” We have not yet found the bottom of the barrel (pond?) for duck-based puns, despite serious efforts in this area.
We couldn’t be more thrilled to partner with Jordan and the MotherDuck team to build a generational analytics business that expands performance and access to analytics, thereby contributing to better decision-making with data. #herewego.