See our updated thoughts about foundation models here.
Five years ago, a paper at the NeurIPS scientific conference changed the course of the artificial intelligence world. “Attention is All You Need” gave rise to what we today refer to as Foundation Models by way of the transformer deep learning architecture.
Today, foundation models such as GPT-3, PaLM, Flamingo, DALL-E, Stable Diffusion, Make-a-Video, and others are trained on broad data sets. They are, therefore, widely adaptable to a range of downstream tasks like text, image, and video generation, as well as text summarization. This technology pattern has produced some inspiring, even moving, early results. But the applications that sit on top of foundation models are often best described as proofs of concept. They are not becoming useful nearly as fast as the underlying models are improving. Developers are up against the labor, resources, and capital required to build a functioning application on top of a foundation model, which leaves startups facing a daunting climb to stay in the game.
In that weakness, we see a huge unmet need and, therefore, opportunity. Many applications that sit on top of foundation models will continue to underwhelm until developers gain access to better tooling. Our industry — founders, big tech, academics, developers, open-source communities, and investors — needs to fill that critical tooling gap to realize the true promise of foundation models.
Evolution of Foundation Models
In the past, practitioners faced a limit on how much training data they could stuff into a deep learning model. Too much data (or too many adjacent data sets) would produce confused models with inferences that were not useful for any given topic. So, we trained lots of smaller, task-specific models instead. But task-specific models were never very good at generalizing beyond the data types they happened to be trained upon or for other tasks. So, if an application developer wanted to support some great adjacent new use case, she had to wait for new data sourcing, annotation, and training of a whole new model before bringing that new use case to life for customers.
The key insight of “Attention is All You Need” is that we can teach deep learning models to “pay attention” and tune their own mathematical weights according to what is most important for the task at hand. That insight has enabled practitioners to train deep learning models on arbitrarily large volumes of training data to address a broader set of potential use cases.
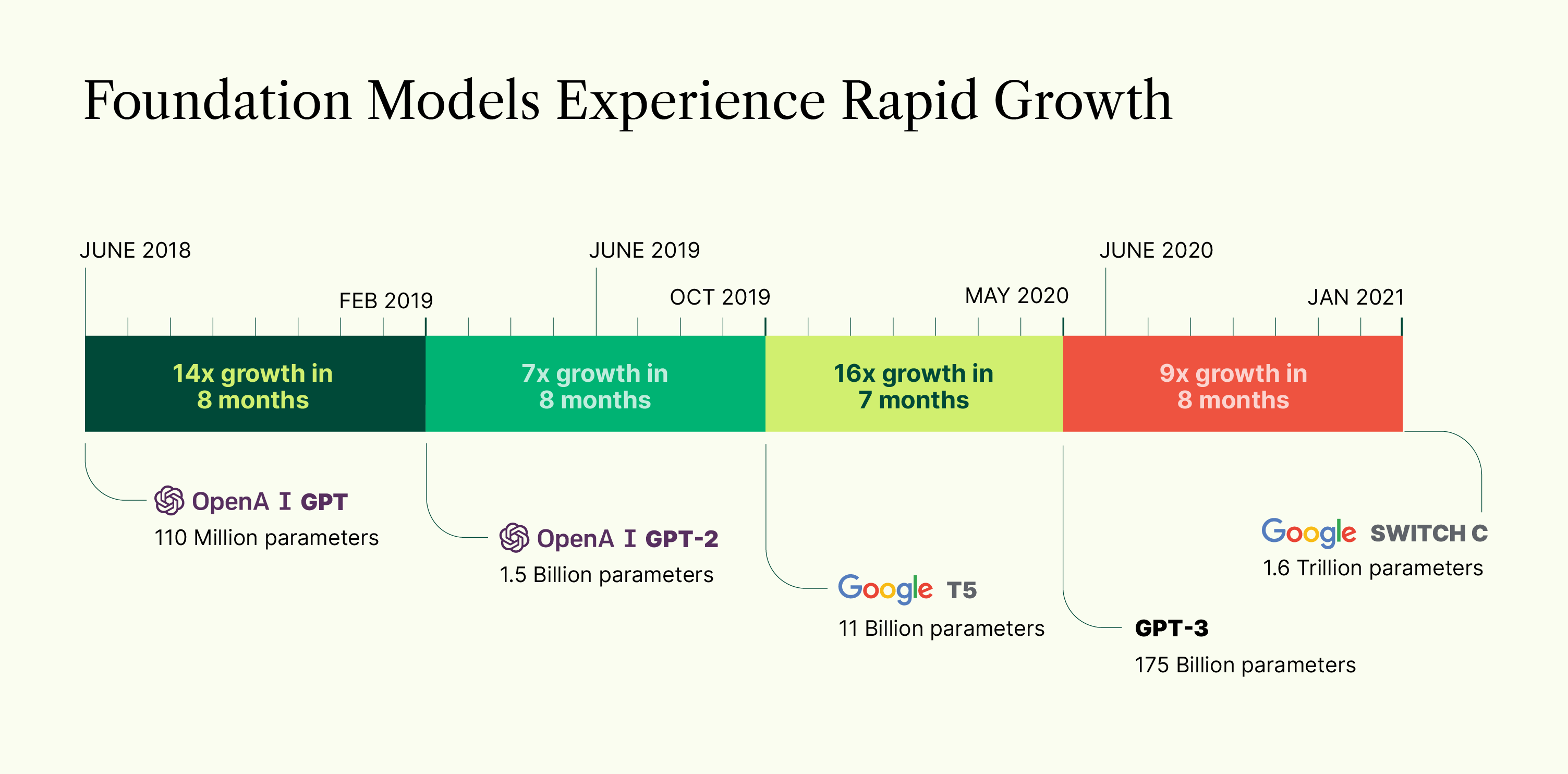
Unshackled by the old training data limitations, practitioners have now tested dramatic increases in scale. A 2018 model called GPT was trained with 100M parameters. GPT-3, released in 2020, was trained with 175B parameters — a whopping 1,750x increase in just two years. Google has since then produced a model that scales up to 1.6T parameters, and Beijing Academy of Artificial Intelligence has gone up to 1.75T — that is roughly 9X and 10X, respectively, versus GPT-3 from 2020! While creating these new large models can cost $10M or far more to train, each new generation has produced an increase in accuracy and flexibility that entices the whole industry to push further ahead.
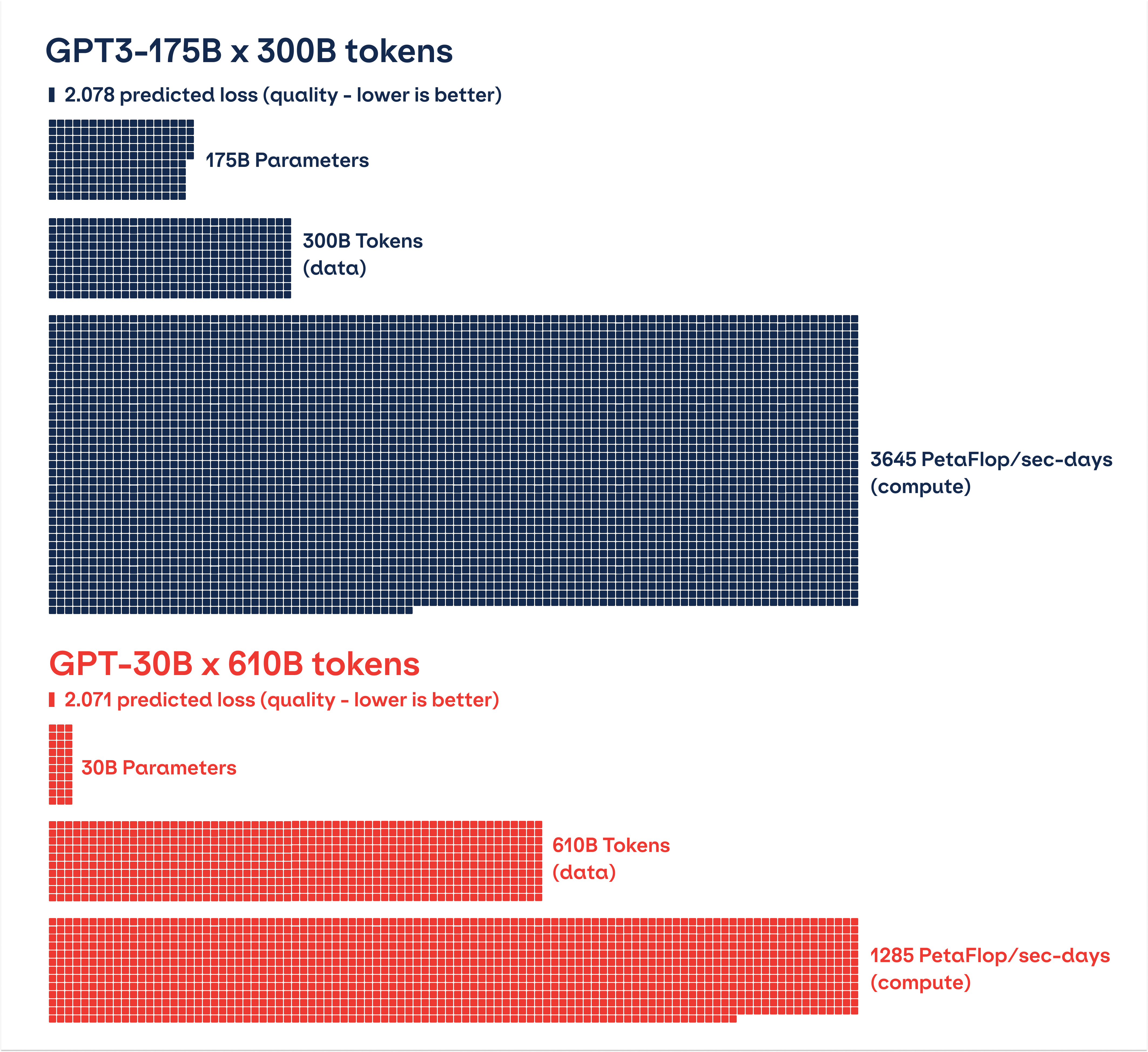
It’s not clear how big these models are going to get. Research has shown that, at least in language-centric models, bigger models gain new “emergent” capabilities that are not simply scaled-up versions of what their smaller siblings could do. But we also know that quality and quantity of training data matter even more than model size. Putting those insights together, we see that the next generation of foundation models can simultaneously become leaner and more powerful. But it is safe to say that the growth of training data volumes, and the pace of investment, will only continue or accelerate.
All deep learning models are limited by the training data they have seen. But such vast volumes of training data mean these models are useful for a wide variety of tasks, not only the specific tasks for which they were designed. Some people call them “foundation models” because a wide variety of applications can be built on top of them. These models started with a focus on text but have now started incorporating images and video too.
Today’s applications
Exciting, inspiring, mind-blowing applications have been built on top of the foundation models. GitHub Co-Pilot, for example. Developers describe the code they plan to write in English, and Co-Pilot suggests ten original, working code blocks that accomplish the developer’s desired task. Jasper and Copy.AI are two other examples that use brief descriptions to generate original marketing copy for landing pages, advertisements, social media, and more. OpenAI’s foundation models are free for anyone to try and provide a glimpse of what’s to come. For example, a user can try asking the models to summarize a scientific publication for a 6th-grade reading level or draw a picture of Super Mario in the style of Soviet Propaganda. Artists have started to explore foundation models as a new medium for expression — here’s one inspiring example.
![]()
Lots of powerful new applications are possible with these foundation models. Here are just a few we imagine customers would like:
- Classify financial transactions to identify payments, fraud detection, expense deduction, etc.
- Extract the 50 most important data points from an individual borrower’s mortgage application packet (annual income, sources of income, demographic information, etc.).
- Summarize insurance claims into a consistent format to automate prior authorization requests.
- Identify which Salesforce pipeline opportunities are ready to convert and may need attention.
- Classify insights from win/loss reports of a sales field into actionable trends and leadership guidance.
- Automatically generate stock images and video for marketing campaigns and optimize them to produce the best conversions.
The challenge
The problem developers face today is the heavy friction that makes it difficult to build great applications on top of the foundation models. First, running these models requires specialized hardware such as GPUs and a massive amount of compute. That imposes operational constraints that severely limit the throughput and concurrency available to developers. It also imposes fees so high that it’s untenable for even basic use cases. Developers try to address this by using older generation models wherever possible, or they’ll try open-source versions of smaller models or train task-specific models of their own. But those approaches undermine the reasons to use foundation models in the first place.
Second, the models don’t “just work” because they’re meant to be only one component of a broader software stack. Coaxing the best possible inferences from the foundation models today requires each application developer to take many ancillary steps. For example, GPT-3 finished training in late 2019, meaning that the model does not know today’s weather or stock prices and has never heard of COVID-19. So, developers must invent their own tools for steps such as prompt engineering, fine-tuning, distillation, and assembling and managing pipelines that refer queries to the appropriate endpoint.
Third, the foundation models demand to be treated with kid gloves because we never quite know what they will say or do. Generative models, such as DALL-E or GPT-3, are often “right,” but it can be devilishly hard to identify when they’re “wrong.” Still more challenging, training foundation models on data sourced from the open internet means we’re holding up a mirror to society’s darkest corners. We risk biased, offensive, and tangential results. The providers of these models, and the application developers who build on top of them, must accept the responsibility of managing those risks.
The result of these challenges is that the applications that use foundation models are not evolving nearly as fast as the models themselves. With all this excitement, there are only a handful of meaningful standalone applications (Github, CoPilot, and Jasper/Copy.ai) that have been met with success thus far. Good ideas abound, but founders continually have difficulty leveraging these foundation models in their next-generation applications. What a paradoxical place we’ve landed in: The use cases just waiting to be served by foundation models are not getting served. Large technology companies are training even newer, even bigger new models, and that will bring even more possibilities into view. But those new models alone won’t make it easier to bring those possibilities to life.
The opportunity
If we consider large-scale foundation models as a new application platform, drawing out the broader application stack surrounding them points to an opportunity within.
Looking at the stack above, there is a gap in the tooling layer between the foundation models and the applications themselves. And in those gaps, we see three major opportunities.
MLOps — existing MLOps players make it easier to deploy internal ML models but building third-party applications on top of foundation models “as a service” requires different steps that developers today must handle themselves. One of these challenges is “prompt engineering,” which involves optimizing for the right prompts or interpretation of prompts to generate quality outputs at scale. Another common challenge is fine-tuning a foundation model on the correct data set to create a use-case-specific “derivative model,” which eliminates the need to train a model from scratch and will likely result in better performance. Some other challenges around productionizing foundation models include distillation/retraining for more efficient performance and cross-platform support of multiple foundation models. Security and reliability are also important questions here.
Data Quality — Garbage in, garbage out. Whether fine-tuning a foundation model or training a new one from scratch, ML models rely on the data that trains them. Companies that hope to use machine learning to build intelligent applications need to have confidence that their data is high fidelity – and that they select the right subset of data on which to train their models. For example, past a certain point, it may not make sense to train on further data redundancies — a smaller but representative sample of images may be more important than the umpteenth cat above a sofa. Companies need the tools to ensure the quality of their data and analytics, but this especially matters in training, fine-tuning and deploying ML models. Data is a huge differentiator here — and the quality of that data matters!
Observability — Developers who rely on foundation models will share responsibility with the model providers to ensure a safe and relevant experience for end customers. For the developers to do their part, they will need tools to observe and manage the inputs and responses anonymously.
Unleash the power of foundation models
We’ve only begun to scratch the surface of what is possible with large-scale foundation models, both at the model and at the application layer. Big tech companies and well-capitalized startups are investing heavily in even bigger and better models. But many of the applications that sit on top of those models will continue to underwhelm until our industry provides developers with better tooling. That work will be done by a combination of big tech, founders, academics, developers, open-source communities, and investors. It’s up to all of us to make the future happen faster in AI-driven applications. And we are excited to see what new ideas entrepreneurs come up with to help unleash the true power of foundation models and enable the widespread innovation and influence everyone expects.
At Madrona, we have already made multiple investments in this space and are committed to helping make the future happen faster. If you are a founder building applications, models, tooling, or something else in the space of foundation models and would like to meet, get in touch at: [email protected].
Related Insights
