
A famous quip is that people always overestimate the change that will occur in a year and underestimate the change that occurs in ten years. The past year has been an exception to this rule catalyzed by the launch of ChatGPT and the rapid embrace of applied AI technologies. In December 2022, I asked a prestigious management consultant how often his clients were asking about GenAI, and he said they almost never raised that question. Just six months later, every CEO was asking their leadership teams: What is our GenAI Strategy?
At Madrona, our front-row seat to this transformation has affirmed several of our expectations about how 2023 would play out. Early in the year, we believed in the breadth of models (especially Open Source), the rise of AI “middleware,” and the opportunity for incumbent SAAS software companies to rapidly enhance their offerings with GenAI. These predictions have gained commercial traction. Major innovations, including Low-Rank Adaptation (LoRA’s), Retrieval Augmented Generation (RAG), and prompt engineering, were barely understood from a commercial perspective back then. But, by our October 2023 Intelligent Application Summit, all these topics were broadly discussed.
As we approach 2024, three macro trends are likely to continue accelerating the pace of change in Applied AI. They are:
- From Models to Model “Cocktails” and Application Orchestration
- From Prototype to Production and the critical role of data
- From “Let’s Try” to ROI
Models to Model Cocktails
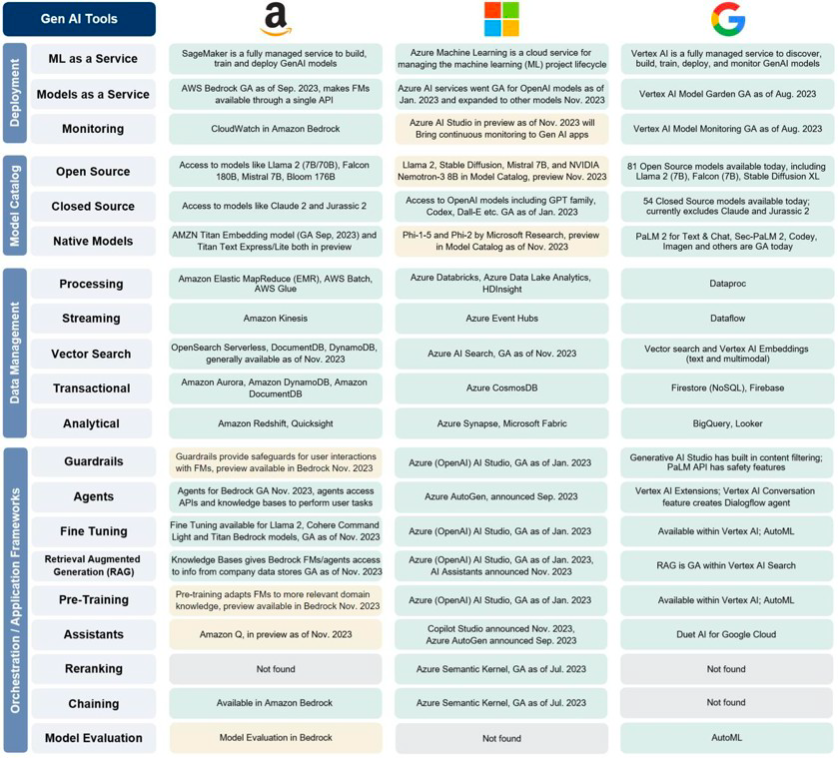
We wrote extensively about the focus on model cocktails in conjunction with Amazon’s recent AWS re:Invent Summit and Microsoft’s Ignite Conference. In addition, Ben Thompson has a recent, relevant post in Stratechery. Bedrock is Amazon’s AI models-as-a-managed service that sits above the hardware/infrastructure and below foundation models to help customers tailor and orchestrate those models for deployment in the context of applications. As outlined in AWS CEO Adam Selipsky’s keynote, Bedrock is the core link between the bottom and top layers in their Generative AI Stack.

Microsoft chose to focus on their application layer “co-pilots” during their Ignite conference earlier in the fall. But CEO Satya Nadella did preview an offering called Models-as-a-Service, which is functionally similar to AWS Bedrock. In addition to these large cloud players, we expect Nvidia and emerging companies like HuggingFace and OctoML to play increasingly strategic roles in orchestrating the layers of the AI stack to empower intelligent applications.
Beyond the broader models-as-a-service platforms, RAG, LoRA’s , prompt engineering and other forms of model customization and personalization are becoming commonplace. There will be many variations on those tools in the year ahead. Application builders are prototyping through prompting on OpenAI’s leading edge but expensive models, then doing their fine-tuning and integrations on a lower cost (often open source) model. We also see prompt engineering evolving to a developer platform as referenced in this recent piece from Vertex. Specifically, “developers will program declaratively, and compiler-like functions will translate these tasks, SLAs, and I/O guarantees into optimized prompts.” While these advances continue, products, including Github Co-pilot and AWS CodeWhisperer, will apply more tailored foundation models and workflows to increase the speed and efficiency of software development. These trends will all create a virtuous cycle for AI-driven innovation and new application orchestration frameworks will emerge.
Prototype to Production
For many companies, 2023 was a year of GenAI early learning and prototyping. Companies often learned that their data was not ready for model training, fine-tuning, or use in a vector database (for RAG). Companies like unstructured.io emerged to help with the data pipelines for accessing, preparing, and cost-effectively using data. That progress lets you ingest data, but developers often found that these models were too expensive or too unpredictable to scale in production (inference).
Companies and customers increasingly understand the power and value of data and metadata to train or fine-tune a model. The direct content and “data exhaust” from the Internet were largely used to train foundation models like OpenAI’s GPT4 and Anthropic’s Claude. But there is so much more data and metadata needed to turn general-purpose models into tailored models that fit a domain, a company, or even a specific customer’s needs. In 2024, a “data hierarchy” is likely to emerge where broad Internet data will be largely accessible, domain-specific data will be directly or indirectly monetizable, and company/customer data will be leveraged for tailored and personalized use.
Morgan Stanley – (click to expand)
2024 will be an important year for domain-specific models in areas like life sciences, financial services, and software development. These models will enable companies to move from prototype to production. Whether those models predict protein structure, price financial securities, or write custom code, they will be developed and differentiated based on the data from specific sectors. The aspect that is harder to predict here is how accessible data at the different layers will become. Domain-specific data and metadata are largely viewed as proprietary, and a company needs to take a long-term perspective to make some amount of domain data broadly accessible in pursuit of its ultimate strategies. As it has done in areas like protein folding prediction in life sciences, the research and open data movement will offer a base level of open data. However, the value in differentiated data, metadata, and model weights associated with intelligent applications will become increasingly valuable. As the commercial value of using differentiated data and running engaging domain models increases, the economics and regulatory implications of data rights will rise. After all, early winners should be positioned to create AI flywheels of training data, models, engagement, and usage/feedback data.
“Let’s Try” to ROI
As companies move from prototype to production, they will realize that the biggest cost of applied AI is inference and not training. Training may be talent and data-constrained, but inference will be dollar and compute resource (chips, power, memory) constrained. The same CEOs who asked last spring, “What is our GenAI strategy?” will be asking a different question this coming summer – what is the return on investment (ROI) for our GenAI investments? And, they will have the CFO and their team following up to validate the answers!
We believe that the three-pronged approach we outlined this year for developing a GenAI strategy, if thoughtfully executed, will continue to serve companies well. The three keys are to ask your customers where they see opportunity for GenAI, partner with established technology companies to rapidly bring capabilities to market, and experiment with start-ups and others on leading-edge, domain-specific use cases.
Prioritized use cases like software developer productivity tools (Microsoft Co-pilot, Amazon Q) and customer service/success assistants are already delivering ROI. Other focus areas include chatbots and AI assistants that help with customer service and customer success. This coming year, various forms of enhanced productivity and increased employee job satisfaction/retention will be a strong source of ROI (albeit initially harder to measure). Both broad offerings, including Microsoft365 Co-Pilot and focused offerings like read.ai, are helping improve personal and team effectiveness. We expect that the intelligent application providers will turn to tools like Statsig to measure the engagement and monitization impact of genAI offerings. By the end of 2024, we anticipate that a series of GenAI cost assessment tools will emerge akin to what happened when cloud consumption took off.
In the short term, we believe incumbent software companies will see substantial top-line upside from pricing premiums for AI enhancements. Companies like Microsoft, Salesforce, Adobe, and more have already announced their “list prices” for such enhancements. And we see the engagement and business value that early adopter customers are experiencing with these offerings. But, exactly how much of that value will be captured by the software companies and how successful the providers will be at selling these capabilities is still to be determined. There will also be breakout companies amongst the Gen-Native startups. The most interesting questions there will be around cost-effective distribution and an ability to build a longer-term “moat” with their offerings.
Concluding Thoughts
Last year felt like an overnight success for GenAI, but it was a transformative year for leveraging prior AI-related building blocks. What made the year special was the end-user inflection point for applied AI ushered in by ChatGPT. Underlying AI models incorporated diverse data forms and types, human prompts functioned as intuitive inputs, and outputs became generative rather than merely predictive. But, we are just getting started. We believe, like the 1994-1996 period for the Internet, that 2023-2025 will be remembered as among the most transformative periods for generative and applied AI in the world.
There is so much opportunity ahead in 2024 for applied AI. Models will be ensembled, customized and orchestrated into intelligent applications. Open models, data, and evaluation will become more prominent. Early signs of GenAI at the edge will emerge. The importance of model and application governance, regulation, safety and transparency will expand. Creative and potentially dangerous uses of generative AI will influence the US presidential election year in unpredictable ways. Despite the expected challenges, we remain cautiously optimistic that 2024 will see many intelligent applications successfully and profitably deployed across use cases, functional areas and domains!
