The 5th Annual AWS re:Invent is a week away and I am expecting big things. At the first ever re: Invent in 2012, plenty of start-ups and developers could be found, but barely any national media or venture capitalists attended. That has all changed and today, re:Invent rivals the biggest and most strategically important technology conferences of the year with over 25,000 people expected to be in Las Vegas the week after Thanksgiving!
So, what will be the big themes at re: Invent? I anticipate, from an innovation perspective, they will line up with the 3 layers of how we at Madrona think about the core of new consumer and enterprise applications hitting the market. We call it the “Future of Applications” technology stack shown below.
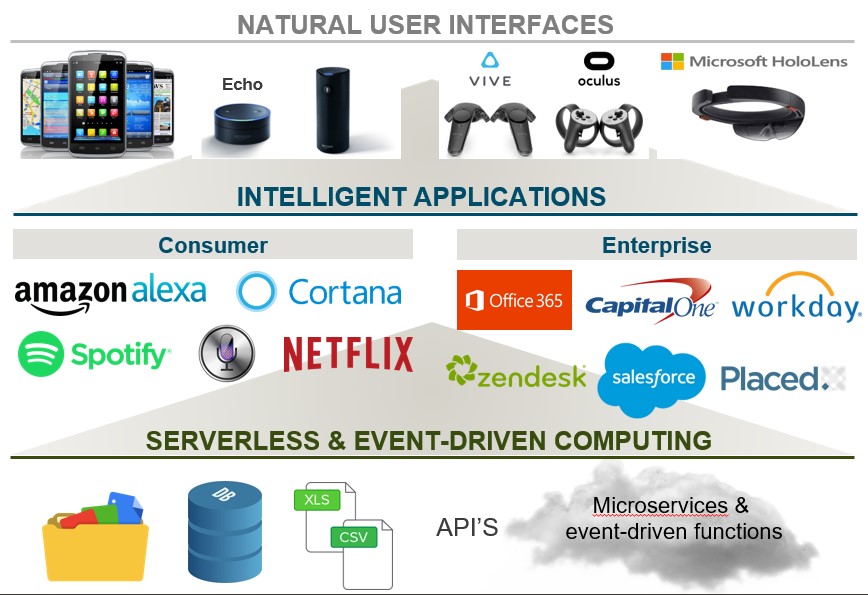
The Themes We Expect at 2016 re:Invent
Doubling Down on Lambda Functions
First is the move “beyond cloud” to what is increasingly called server-less and event-driven computing. Two years ago, AWS unveiled Lambda functions at re:Invent. Lambda quickly became a market leading “event-driven” functions service. The capability, combined with other micro-services, allows developers to create a function which is at rest until it is called in to action by an event trigger. Functions can perform simple tasks like automatically expanding a compute cluster or creating a low resolution version of an uploaded high resolution image. Lambda functions are increasingly being used as a control point for more complicated, micro-services architected applications.
I anticipate that re:Invent 2016 will feature several large and small customers who are using Lambda functions in innovative ways. In addition, both AWS and other software companies will launch capabilities to make designing, creating and running event-driven services easier. These new services are likely to be connected to broader “server-less” application development and deployment tools. The combination of broad cloud adoption, emerging containerization standards and the opportunities for innovating on both application automation and economics (you only pay for Lambda functions on a per event basis) presents the opportunity to transform the infrastructure layer in design and operations for next-generation applications in 2017.
Innovating in Machine and Deep Learning
Another big focus area at re:Invent will be intelligent applications powered by machine/deep learning trained models. Amazon already offers services like AWS ML for machine learning and companies like Turi (prior to being acquired by Apple) leveraged AWS GPU services to deploy machine learning systems inside intelligent applications. But, as recently reported by The Information, AWS is expected to announce a deep learning service that will be somewhat competitive with Google’s TensorFlow deep learning service. This service will leverage the MXNet deep learning library supported by AWS and others. In addition, many intelligent applications already offered to consumers and commercial customers, including AWS stalwarts such as Netflix and Salesforce.com, will emphasize how marrying cloud services with data science capabilities are at the heart of making applications smarter and individually personalized.
Moving to Multi-Sense With Alexa, Chat and AR/VR
While AWS has historically offered fewer end-user facing services, we expect more end-user and edge sensors/devices interactions leveraging multiple user interfaces (voice, eye contact, gestures, sensory inputs) to be featured this year at re:Invent. For example, Amazon’s own Alexa Voice Services will be on prominent display in both Amazon products like the Echo and third party offerings. In addition, new chat-related services will likely be featured by start-ups and potentially other internal groups at Amazon. Virtual and augmented reality use cases for areas including content creation, shared-presence communication and potentially new device form factors will be highlighted. Madrona is especially excited about the opportunity for shared presence in VR to reimagine how people collaborate with man and machine (all powered by a cloud back-end.). As the AWS services stack matures, it is helping a new generation of multi-sense applications reach end users.
Rising Presence of AWS in Enterprises Directly and With Partners
Two other areas of emphasis at the conference, somewhat tangential to the future of applications, will be the continued growth of enterprise customer presentations and attendance at the conference. The dedicated enterprise track will be larger than ever and some high-profile CIO’s, like Rob Alexander from Capital One last year, will be featured during the main AWS keynotes. Vertical industry solutions for media, financial services, health care, and more will be highlighted. And, an expanding mix of channel partners, that could include some surprising cloud bedfellows like IBM, SAP and VMWare, could be featured. In addition, with the recent VMWare and AWS product announcements, AWS could make a big push into hybrid workloads.
AWS Marketplace Emerging as a Modern Channel for Software Distribution
Finally, the AWS Marketplace for discovering, purchasing and deploying software services will increase in profile this year. The size and significance of this software distribution channel has grown significantly the past few years. Features like metered billing, usage tracking and deployment of non “Amazon Machine Image (AMI)” applications could see the spotlight.
Over the years, AWS has always surprised us with innovative solutions like Lambda and Kinesis, competitive offerings like Aurora databases and elastic load balancing, as well as customer centric solutions like AWS Snowball. We expect to be surprised, and even amazed, at what AWS and partner companies will unveil at re: Invent 2016.


